0x00 前言 (PS:别问我为啥这么长时间都没发文章,我懒~~~~地回答你)
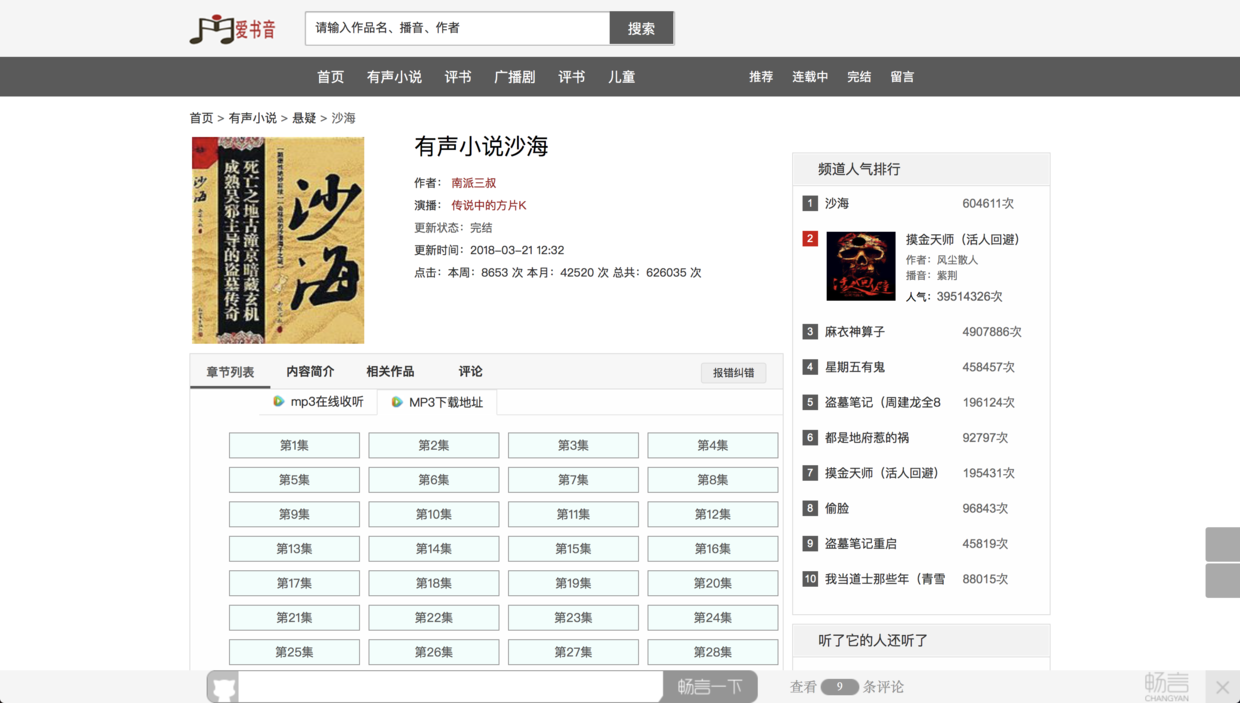
最近对一个热播的电视剧《沙海》貌似挺感兴趣的,与其是我这种对电视剧几乎免疫的来说。(PS:张铭恩好帅!!!),然而电视剧的每周更新速度太慢,不如借此时间看看原著,奈何老妈眼睛有些老花眼,整天看平板又累眼,于是我便从网上找了读书的音频下载下来,让老妈可以直接听了。但是在好不容易找到一个网站之后,下载起来却有些麻烦了,竟然要一个一个下载。
0x01 开发环境
开发环境: OS X, Python 3.5
依赖包: requests, BeautifulSoup4
如果没有requests的基础的话,建议先看完本文之后点个赞,然后关掉。我才不会告诉你这些是什么,怎么用呢,哼~。(>人<;)
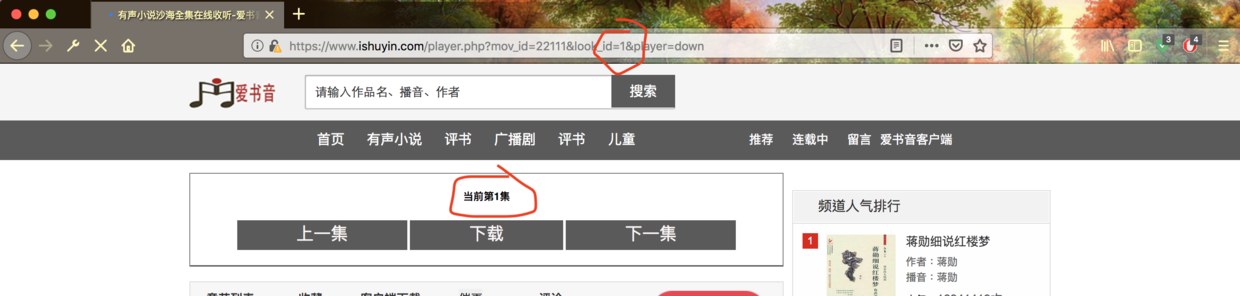
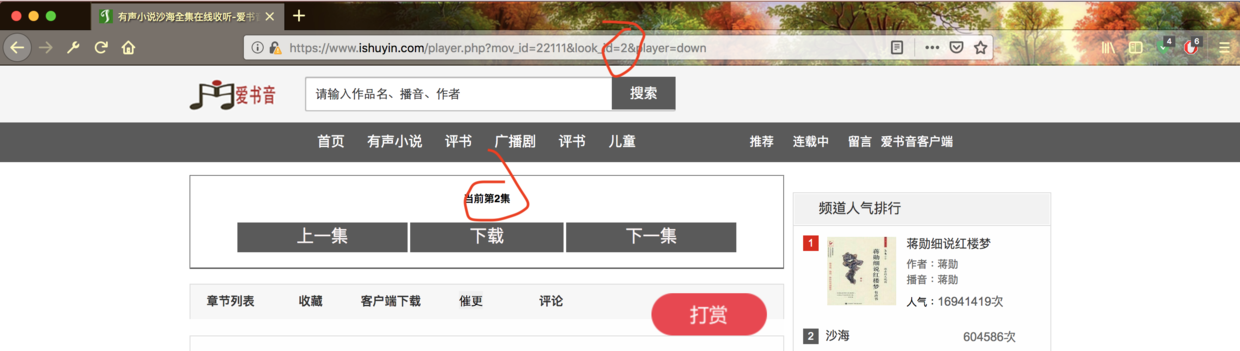
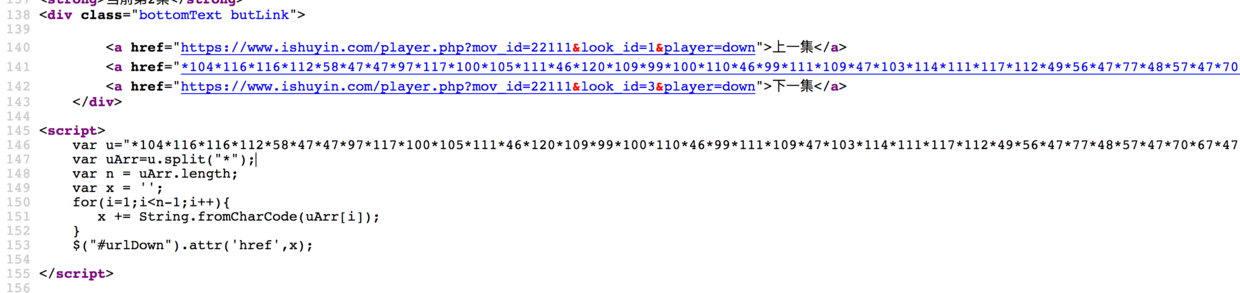
0x02 随手写一个爬虫 既然我们是要爬取全部的音频,我们肯定要先分析一下规律。)  ̄︿ ̄)
等等,哪里不太对,这个是js写的,但是我们用requests直接get到的页面是加密的!呃,写个python版的解密函数,好麻烦,懒~~~,(lll¬ω¬) 有现成的js解密,我们直接调用不好么。
锵锵锵锵,拿出js的杀手锏,(≧∇≦)ノ execjs库 解决这个问题。
一个简单的官方演示:
1 2 3 4 5 6 7 8 9 10 >>> import execjs>>> execjs.eval ("'red yellow blue'.split(' ')" )['red' , 'yellow' , 'blue' ] >>> ctx = execjs.compile (""" ... function add(x, y) {... return x + y;... }... """>>> ctx.call("add" , 1 , 2 )3
所以我就把它的解密函数封装成一个python函数来解决这个问题。
1 2 3 4 5 6 7 8 9 10 11 js = execjs.compile (""" function add(u) { var uArr=u.split("*"); var n = uArr.length; var x = ''; for(i=1;i<n-1;i++){ x += String.fromCharCode(uArr[i]); } return x; } """ )
完美解决,哇咔咔咔。( ̄︶ ̄)↗
0x03 完整代码演示 ⚠️: 代码仅供用于学习研究,如用做其他事务所产生的后果,这个锅我不背啊|・ω・`)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import requests, os, execjs, timefrom bs4 import BeautifulSoup as bsLAST = 243 + 1 URL = "https://www.ishuyin.com/player.php?mov_id=22111&look_id={}&player=down" js = execjs.compile (""" function add(u) { var uArr=u.split("*"); var x = ''; for(i=1;i<uArr.length-1;i++){ x += String.fromCharCode(uArr[i]); } return x; } """ )def download (url, filename ): """ Download the file of the URL Args: url: URL filename: Saved file name Returns: NULL """ r = requests.get(url) with open (filename, "wb" ) as code: code.write(r.content) def main (): for i in range (0 , LAST): time.sleep(1 ) request = requests.get(URL.format (i)).text request = bs(request, features="lxml" ).find(id ="urlDown" ) request = js.call('add' , request['href' ]) print ('start download 沙海{}.mp3' .format (i)) download(request, "沙海{}.mp3" .format (i)) if __name__ == '__main__' : main()
0x04 后记 唔,其实这个问题也有别的解法的说,我懒得写~~(  ̄ー ̄)
老妈开心就是最棒的啦ヾ(≧▽≦*)o
如果本文看完了或者帮到了你,那就点赞或者打个赏吧,我才不会谢谢你,哼~